
“当咱们通盘东说念主齐在过圣诞的时候体育游戏app平台,一个中国实验室却发布了摇荡天下的AI模子。这显著具有象征有趣。永恒以来,好意思国齐在AI竞争中处于寰球当先地位,但DeepSeek的最新模子却在转变这一时势。” Scale AI的创举东说念主兼CEO亚历山大·王(Alexandr Wang)在接受好意思国媒体采访时这样感触。
短短半个月时刻,一款中国实验室发布的AI模子就用令东说念主难以置信的实力数据,摇荡了通盘硅谷AI鸿沟。从科技巨头到AI新贵再到时间群众,险些通盘东说念主齐感受到了来自中国AI行业的强烈冲击。更令东说念主战抖的是,中国AI行业在遭遇出口管制和算力匮乏情况下,完好意思了弯说念超车。
横空出世空降登顶
这个实验室便是来自中国的DeepSeek,2023年刚刚创建。他们在客岁年底发布了一个免费开源的大语言模子。凭据该公司发表的论文,DeepSeek-R1在多个数学和推理基准测试中超越了行业当先的OpenAI o1等模子,更在性能、资本、敞开性等观点方面压倒了好意思国AI巨头。
科技行业需要用数据话语。在一系列第三方基准测试中,DeepSeek的模子在从复杂问题处置到数学和编程等多个鸿沟的准确性上,超越了Meta的Llama 3.1、OpenAI的GPT-4o以及Anthropic的Claude Sonnet 3.5。
就在上周,DeepSeek又发布了推理模子R1,相似在诸多第三方测试中超越了OpenAI最新的o1。在AIME 2024数学基准测试中,DeepSeek R1取得了79.8%的获胜率,高出了OpenAI的o1推理模子。在圭臬化编码测试中,它展示了“群众级”的发扬,在Codeforces上得到了2,029的Elo评分,高出了96.3%的东说念主类竞争敌手。
Scale AI则使用了“东说念主类临了熟习”(Humanity’s Last Exam)来测试AI大模子,它接管来自数学、物理、生物、化学拔擢提供的“最难问题”,波及最新的照管遵守。在测试了通盘最新的AI模子后,亚历山大·王不得不惊羡,DeepSeek的最新模子“践诺上是发扬最出色的,或者至少与o1等最好的好意思国模子不相高下”。
绝不夸张地说,DeepSeek在好意思国AI行业激勉了一形式震,更激勉了媒体的争相报说念。险些通盘的主流媒体和科技媒体,齐报说念了中国AI模子高出好意思国这一爆炸新闻。短短几天时刻,DeepSeek就依然成为苹果应用商店排行第一的免费应用,力压OpenAI的ChatGPT。
性能资本摇荡巨头
实打实的测试对比扫尾,不得抗争。险些通盘的AI巨头、风投和时间东说念主员齐只可承认,在大模子这个鸿沟,DeepSeek至少依然不错和OpenAI平起平坐,中国依然追上了好意思国。
微软首席实行官萨蒂亚·纳德拉(Satya Nadella)活着界经济论坛上谈到DeepSeek时清晰:“DeepSeek的新模子令东说念主印象深化,他们不仅灵验地构建了一个开源模子,有时在推理筹画时高效运行,况且在筹画遵守方面发扬出色。咱们必须相称相称崇拜地对待中国的AI高出。”
中国AI不仅是性能超卓,更是经济实惠。让硅谷诸多AI巨头感到摇荡和汗颜的是DeepSeek的便宜资本。R1模子的查询资本仅为每百万个token 0.14好意思元,而OpenAI的资本为7.50好意思元,使其资本裁汰了98%。
确切是小米加步枪,DeepSeek只是用了两个月时刻,破钞了不到600万好意思元就打造了大语言模子R1,况且他们用的照旧性能较弱的英伟达H800芯片。这意味着什么?打个譬如,中国AI公司果然开着浅显轿车,就完好意思了弯说念超车,在竞赛中超越了硅谷巨头们的超等跑车。
除了熟习资本便宜,DeepSeek的团队构成也与硅谷诸多AI巨头大相径庭。DeepSeek创举东说念主梁文峰在组建照管团队时,并未寻找教养丰富的资深软件工程师,而是专注于来自北大、清华等顶级高校的博士生。许多东说念主曾在顶级学术期刊发表论文,并在海外学术会议上获奖,但穷乏行业教养。
“咱们的中枢时间岗亭主要由本年或往常一两年毕业的东说念主员担任,”梁文峰在2023年接受媒体采访时清晰。这种招聘战略有助于营造一个解放结合的公司文化,照管东说念主员不错专揽弥散的筹画资源来开展不拘一格的照管方式。这与中国传统互联网公司酿成昭着对比,在后者中,团队频频为资源争斗浓烈。
莫得囤积顶级GPU,莫得收受资深AI东说念主才,莫得焕发的运行资本,一样不错拿出最好的大模子,DeepSeek的一切齐让硅谷AI巨头们感到颓落。
硅谷巨头堕入颓落
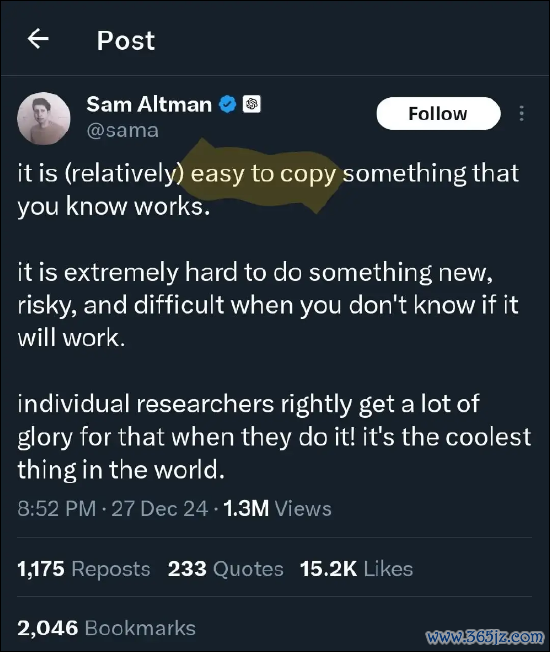
被挑战的巨头们是如何看待DeepSeek呢?OpenAI创举东说念主兼CEO奥特曼(Sam Altman)的表态让东说念主嗅觉有点酸。他在酬酢媒体上清晰:“复制已知灵验的决策相对容易,但探索未知鸿沟则充满挑战。” 这一言论被平庸解读为对DeepSeek的暗讽,清晰中国AI模子穷乏简直的立异,只是是在复制现存的灵验方法。
Perplexity AI的CEO斯林尼瓦斯(Arvind Srinivas,印度东说念主)从商场影响的角度来看待这一发布:“DeepSeek在很猛进程上复制了OpenAI o1 mini并开源了它。”但他也惊羡了DeepSeek的快速要领:“看到推理如斯飞快地商品化,这有点豪恣。”他清晰,我方的团队会将DeepSeek R1的推明智商引入Perplexity Pro。
Stability AI的创举东说念主Emad Mostaque清晰DeepSeek的发布给资金更充裕的竞争敌手带来了压力:“你能遐想一个筹集了10亿好意思元的前沿实验室咫尺无法发布其最新模子,因为它无法打败DeepSeek吗?”
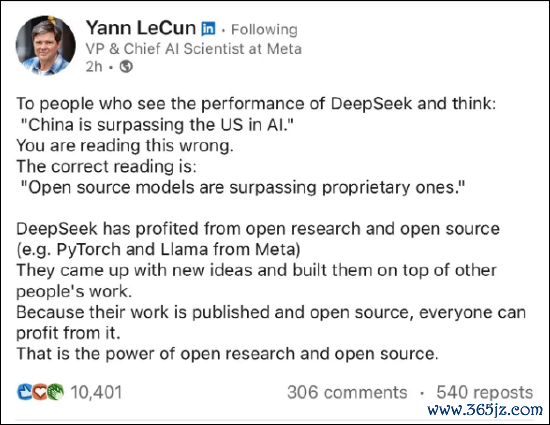
Meta AI首席科学家杨立昆(Yann
LeCun,法国东说念主)则强调中国东说念主是依靠开源的上风取得获胜。他在对DeepSeek的获胜清晰救济的同期强调,DeepSeek的获胜并非意味着中国在AI鸿沟超越好意思国,而是发挥注解了开源模子正在超越闭源系统。
杨立昆清晰,DeepSeek从开源照管和开源代码中受益良多,他们冷漠了新想法,并在他东说念主处事的基础上进行立异。由于他们的处事是公开和开源的,通盘东说念主齐能从中获益。这体现了开源照管和开源代码的力量。 他以为,DeepSeek的获胜提现开源生态系统在鼓励AI时间高出中的紧迫性,标明通过分享和结合,开源模子有时完好意思快速立异和发展。
但Meta里面可莫得这样淡定。往常几天,职场匿名平台teamblind上有一个来自Meta职工的贴子被疯传。帖子称Meta里面因为DeepSeek的模子,咫尺依然进入懆急模式,不仅是因为DeepSeek的优秀发扬,更是因为极低的资本和团队构成。
“一切齐因为DeepSeek-V3的出世,它在基准测试中依然让Llama 4小巫见大巫。更让东说念主疼痛的是,一家中国公司仅用550万好意思元熟习预算就作念到了这少许。咫尺Meta的工程师们正在分秒必争地分析DeepSeek,试图复制其中的一切可能时间。这绝非夸张。况且,照料层正为GenAI研发部门的大宗进入而发愁。当部门里一个高管的薪资就高出熟习通盘DeepSeek V3的资本,况且这样的高管还稀有十位,他们该如何向高层打发?
高效算法弯说念超车
那么,DeepSeek究竟是如何完好意思弯说念超车,在算力显著过期,资本只是零头的情况下,打造出不错忘形以致超越硅谷AI巨头的大模子呢?
好意思国的出口管制严重贬抑了中国科技公司以“西方式”的方法参与东说念主工智能竞争,即通过无穷推广芯片采购并延迟熟习时刻。因此,大多数中国公司将要点放鄙人游应用,而非自主构建模子。但DeepSeek的最新发布发挥注解,获胜的另一条说念路是:通过重塑AI模子的基础结构,并更高效地专揽有限资源。
因为算力资源不及,DeepSeek不得不建筑更高效的熟习方法。“他们通过一系列工程时间优化了模子架构——包括定制化芯片间通讯决策、减少字段大小以粗略内存,以及立异性地使用群众搀杂模子(Mixture-of-Experts)方法,”Mercator照管所的软件工程师温迪·张(Wendy Chang)清晰。“许多这些方法并非簇新,但获胜地将它们整合以坐蓐顶端模子是很是了不得的建立。”
DeepSeek还在“多头潜在把稳力”(Multi-head Latent Attention,MLA)和“群众搀杂模子”方面取得了首要进展,这些时间缠绵使DeepSeek的模子更具资本效益,熟习所需的筹画资源远少于竞争敌手。事实上,据照管机构Epoch AI称,DeepSeek的最新模子仅使用了Meta Llama 3.1模子十分之一的筹画资源。
中国AI照管东说念主员完好意思了许多东说念主以为猴年马月的建立:一个免费、开源的AI模子,其性能不错忘形以致超越OpenAI来源进的推理系统。更令东说念主直爽的是他们的完好意思方式:让AI通过试错自我学习,雷同于东说念主类的学习方式。
照管论文中写说念:“DeepSeek-R1-Zero是一个通过大限制强化学习(RL)熟习的模子,无需监督微调(SFT)当作初步要津,展示了超卓的推明智商。”
“强化学习”是一种方法,模子在作念出正确决策时得到奖励,作念出错误决策时受到刑事拖累,而无需知说念哪个是哪个。经过一系列决策后,它会学会遵从由这些扫尾强化的旅途。
DeepSeek R1是AI发展的一个转机点,因为东说念主类在熟习中的参与最少。与其他在大宗监督数据上熟习的模子不同,DeepSeek R1主要通过机械强化学习进行学习——践诺上是通过实验和得到响应来处置问题。该模子以致在莫得明确编程的情况下,发展出了自我考据和反念念等复杂智商。
跟着模子履历熟习进程,它当然学会了为复杂问题分拨更多的“念念考时刻”,并发展出捕捉本人错误的智商。照管东说念主员强调了一个“顿悟时刻”,模子学会了再行评估其最初的问题处置方法——这是它莫得被明确编程去作念的事情。
开源模子广获救济
值得一提的是,DeepSeek沉静将其立异遵守开源,使其在寰球AI照管社区中得到了更大的救济。 与独到模子不同,DeepSeek R1的代码和熟习方法在MIT许可证下实足开源,这意味着任何东说念主齐不错获取、使用和修改该模子,莫得任何贬抑。
对许多中国AI公司来说,建筑开源模子是赶超西方竞争敌手的独一方式,因为这样不错劝诱更多用户和孝敬者,匡助模子约束成长。在OpenAI迟缓阻滞化确当下,DeepSeek的开源得到了AI从业东说念主员的交口奖饰。
英伟达资深照管员樊锦(Jim Fan)博士推奖了DeepSeek前所未有的透明度,并平直将其与OpenAI的原始处事长短不分。“咱们活命在一个非好意思国公司保捏OpenAI原始处事的时刻线上——简直敞开的、前沿的照管,赋能通盘东说念主,”樊锦指出。
樊锦指出了DeepSeek强化学习方法的紧迫性:“他们可能是第一个展示[强化学习]飞轮捏续增长的开源软件方式。”他还推奖了DeepSeek平直分享“原始算法和matplotlib学习弧线”,而不是行业中更常见的炒作驱动公告。
遵从相似的推理,但带有更严肃的论证,科技企业家Arnaud Bertrand解释说,竞争性开源模子的出现可能对OpenAI冲击雄伟,因为这会使OpenAI模子勉强费意愿强烈的高等用户的劝诱力裁汰,从而毁伤OpenAI的贸易模式。“这基本上就像有东说念主发布了一款与iPhone很是的手机,但售价为30好意思元而不是1000好意思元。这是戏剧性的。”
出口管制面对挑战
这对英伟达来说,DeepSeek的横空出世是一个利空要素。好多AI行业东说念主士不禁开动念念考另一个问题:既然DeepSeek用上一代芯片的阉割版就不错熟习出最刚劲的大模子,那么科技巨头们还需要无间豪恣烧钱抢购英伟达的最新GPU吗?这个问题细念念极恐。
人所共知,因为好意思国政府的AI芯片禁运,中国无法采购英伟达最高性能的AI芯片,而H800则是高算力A100芯片的阉割版。与A100比拟,H800的中枢数目、频率和显存方面显著较低,算力上降幅约莫在10-30%之间,主要不需要顶级算力的场景,举例中等限制的AI熟习与推理任务。H800的内存带宽被贬抑在 1.5 TB/s,而A100 80GB版块可达到 2 TB/s,这将平直影响数据处明智商,尤其在深度学习任务中。
Scale AI的亚历山大·王坚捏以为,DeepSeek的芯片数目可能远远高于外界遐想。他公开清晰,我方以为DeepSeek至少领有5万块H100,他们不会公布具体数字。
H100的算力是A100的六到七倍,这款3万好意思元起售的顶级GPU亦然咫尺硅谷科技巨头们争先抢购的军火。Meta和微软齐高出采购了15万块H100,谷歌、甲骨文和亚马逊齐采购了5万块,马斯克的xAI更部署了10万块H100构成的超等筹画机集群用于熟习大预言模子Grok3。
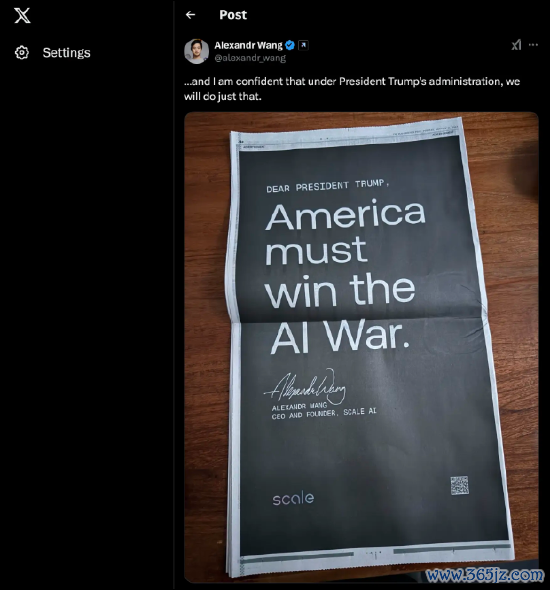
亚历山大·王进一步清晰,将来中国AI行业可能会面对更多挑战,“将来他们将受到咱们依然实施的芯片和出口管制的贬抑,难以再获取更多芯片。”他上周在《华盛顿邮报》购买了整版告白,写说念“好意思国必须赢下这场AI斗争!”
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
拖累裁剪:尉旖涵 体育游戏app平台